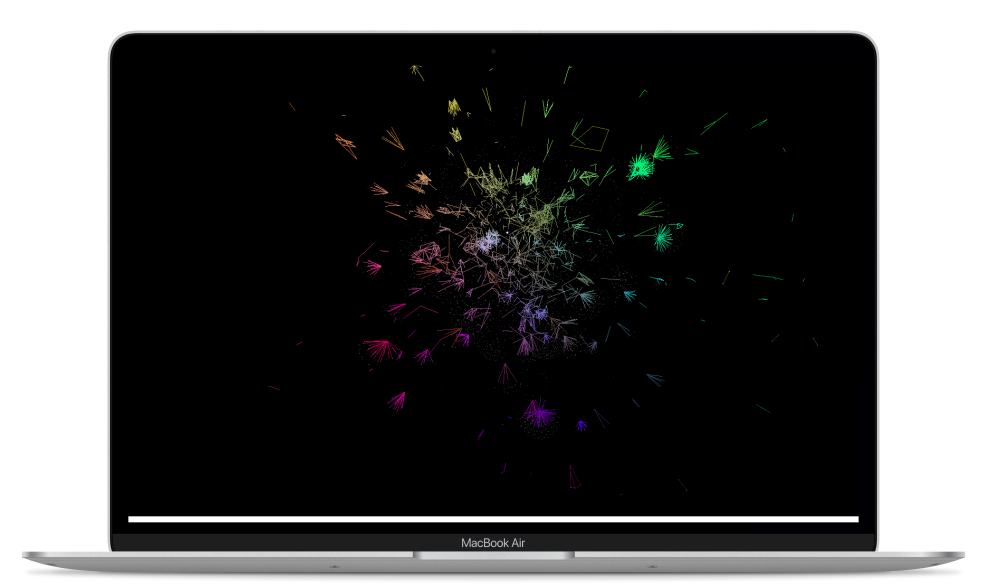
networks commonly used in Economic Complexity to explore bipartite relations such as countries and their exported products. These methods are also useful for different kind of relations such as countries and their spoken languages.
In this post I use the built-in world_trade_avg_1998_to_2000 dataset to produce a proximity network, thanks to our heuristics to visualise large networks we can remove the cutoff points.
# remotes::install_github("pachamaltese/economiccomplexity")library(economiccomplexity)
bi <- balassa_index(world_trade_avg_1998_to_2000)
pro <- proximity(bi)
net <- projections(pro$proximity_country, pro$proximity_product)
The net$network_p object is essentially an edgelist which we can thus simply pass to our initialisation function. Then of course we hide long edges to avoid drawing a hairball. I also use graph_cluster rather than color the links by coordinates which would not truly reveal clusters given the structure of the graph.
The idea is to pull tweets on a specific topic (given a boolean search) and graph the network of Twitter @mentions to visualise hubs of conversations, e.g.: @I tweet @you creates a link between "I" and "you."
We use graphTweets to build the latter. First we pull 15,000 tweets that use the #rstats hashtag.
tweets <- rtweet::search_tweets("#rstats", n = 15000L)
We then use graphTweets to create the network of mentions.
The idea is to pull tweets on a specific topic (given a boolean search) and graph the network of retweets, this gives an idea of how conversations spread throughout Twitter. We use graphTweets to build the latter.
Below we pull 15,000 tweets that use the #rstats hashtag using the retweets filter to optimise the query (we're only interested in retweets).
tweets <- rtweet::search_tweets("#rstats filter:retweets", n = 15000L)
Then I use graphTweets to build the network of retweets, including "quotes" (retweets with a comment).
graphTweets actually returns a list of nodes and edges. After renaming "edges" to "links" we can simply pass this object straight to our initialisation function.
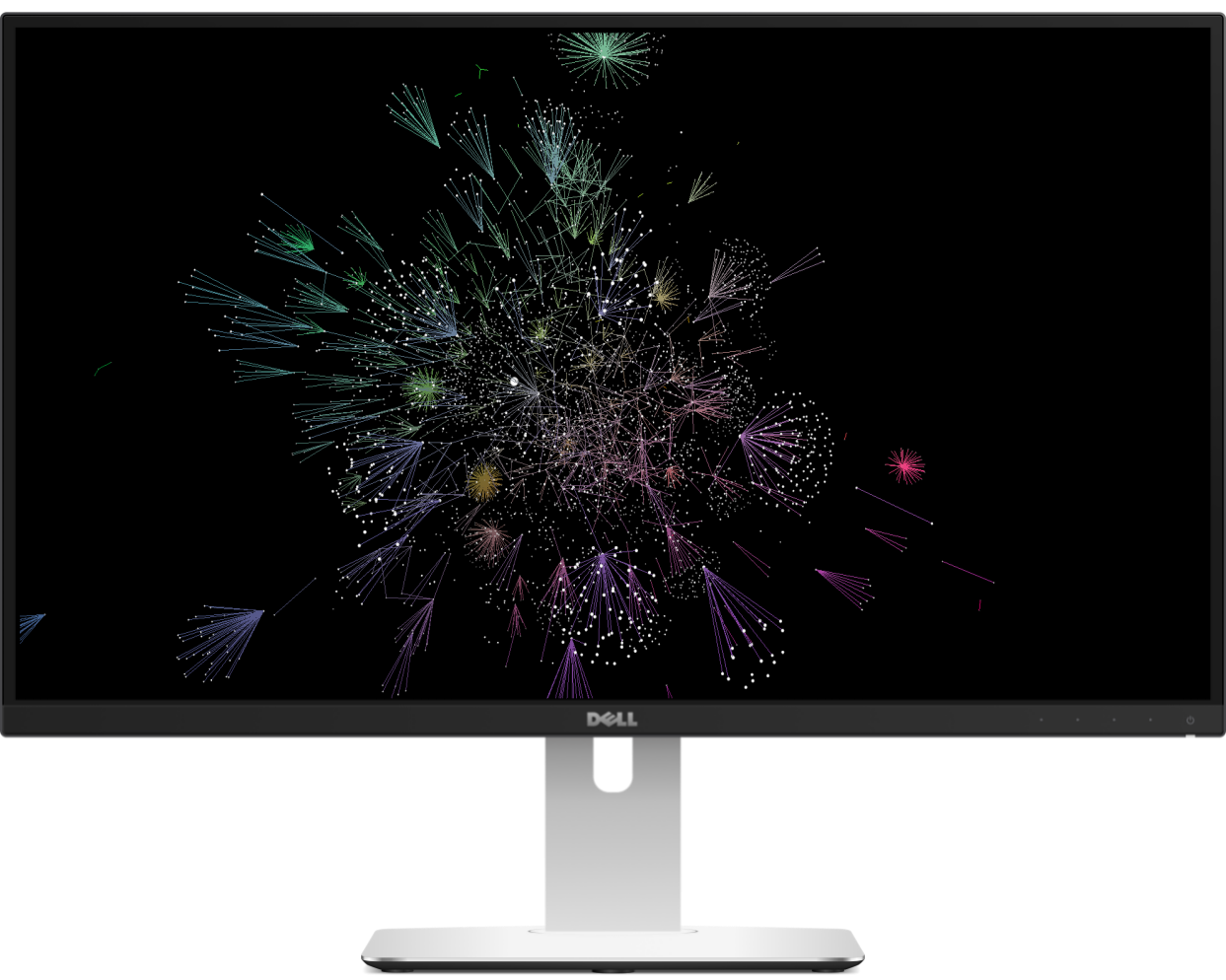
The complete source code is available on Github, and is surprisingly simple. Below is the script used to to generate the visualisation. We'll break it down.
The first function called (cran_deps_graph) generates the network of dependencies as igraph object. Note that I purposely do not include base R packages (the likes of methods or tools) as 1) this visualisation is intended for the R community of open source developers, 2) R base packages are obviously used a lot and make the graph even more of a hairball than it already is, 3) finally they do not really bring new information to the graph and are thus best left out.
By default cran_deps_graph includes three forms of dependencies: Depends, Imports, and LinkingTo. It purposely (perhaps wrongly—feedback welcome) Suggests as these, to my mind, indicate some kind of weaker dependency.
I then use tidygraph by Thomas Lin Pedersen (which I highly recommend) to compute in degree or in this case the number of packages that depend on each other packages.
Finally I build the graph using grapher. Note the use save_graph_json to store the visualisation as JSON, we will read that file in the Shiny app (explained below). This is somewhat unconventional but helps immensely improve the performances in Shiny, you can read more about it in the Shiny guide.
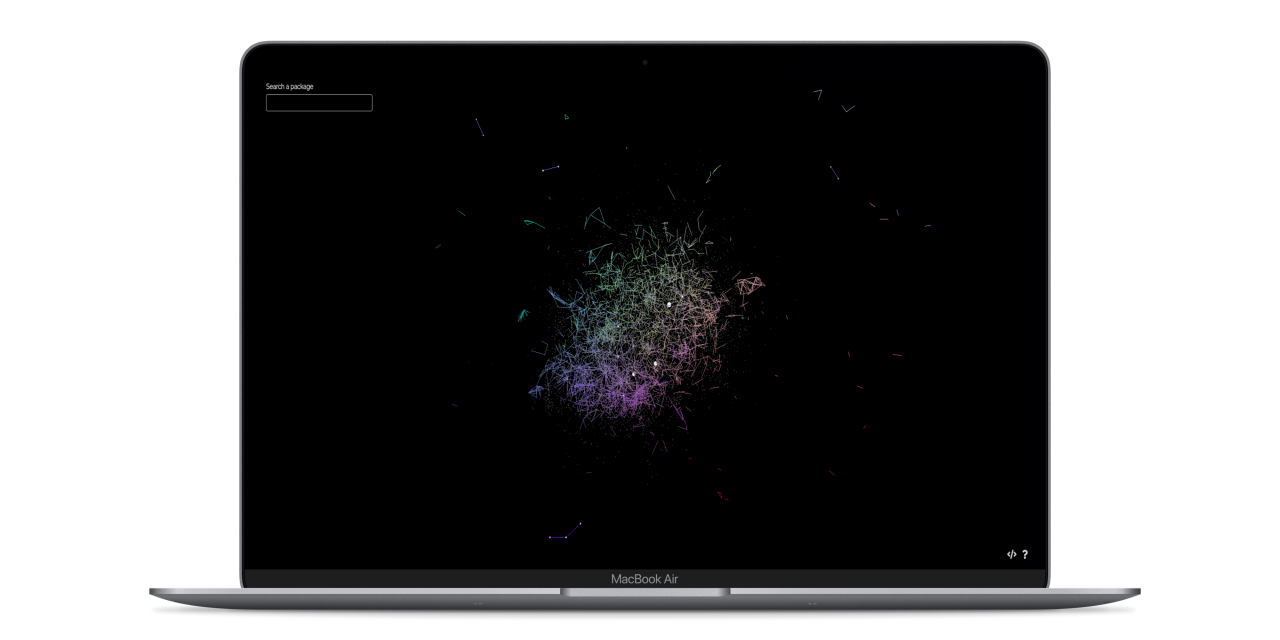
App
I won't cover all the details of application, it's rather straight forward. I will only give a few tips in the event you want to produce something similar.
First, make the grapher visualisation take the entire screen with height = 100vh in graphOutput.
Make the directory containing graph.json available to Shiny with addResourcePath. and pass that path to grapher. This is explained in more details in the Shiny guide.